専門家コラム

近年、生成AIの活用が加速しております。コンタクトセンター業界においてもAIの導入が進んでおり、FAQの自動応答や、オペレーターの支援、さらには会話のリアルタイム翻訳など、多岐にわたる用途でAIが活用されております。
しかし、AIの導入が進む一方で、期待していたほどの効果を得られないという課題も多く聞きます。その原因の一つが「データ整備の不足」です。AIの性能を最大限に引き出すためには、適切なデータの管理・チューニングが不可欠です。本記事では、生成AI活用におけるデータ整備の重要性について、コンタクトセンターの具体例も交えながら解説します。
データ整備が重要な理由
生成AIのパフォーマンスは、提供されるデータの質に大きく依存します。特にコンタクトセンターでは、過去の問い合わせ履歴やFAQ、オペレーターの対応スクリプトなど、多くのデータが蓄積されていますが、これらのデータが適切に整備されていなければ、AIの回答の精度は低下し、むしろオペレーションの混乱を招くことになります。
実際に、2024年にPwCコンサルティング合同会社が実施した調査によると、期待を大きく超えた成果を出した理由として2位、活用効果が期待未満だった1位の理由として「データ品質」が挙げられております。
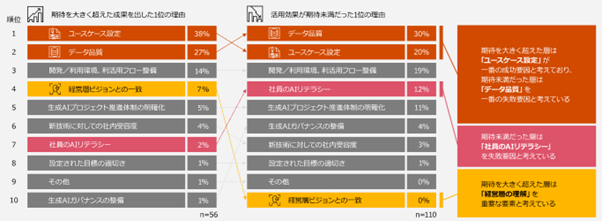
データ品質が整えられないままに進めると期待したような効果が出ず、下記のような問題も起こり得ます。
- 不正確な回答の増加:古い情報や誤ったデータが含まれていると、AIが誤った回答を生成する。
- 適切な情報の検索ができない:ナレッジが分散していると、AIが必要なデータを参照できず、関連性の低い回答を出す。
- データのバイアスや誤情報の拡散:偏ったデータを学習すると、特定の意図に沿った誤った回答を提供する可能性がある。
- セキュリティリスクの増大:顧客の個人情報や機密情報を適切に管理しないと、情報漏洩のリスクが高まる。
これらの課題を解決するためには、データ整備の具体的なポイントを理解し、適切な管理を行うことが重要です。具体的にどのようなデータ整備が求められるのか。そのポイントを詳しく解説していきます。
データ整備における押さえるべきポイント
コンタクトセンターにおけるデータ整備のポイントは多岐にわたります。以下に主要な項目を挙げ、それぞれの詳細を解説します。
ナレッジの統合と一元管理
・FAQデータベース、社内マニュアル、製品仕様書、過去の問い合わせ履歴などを統合。
・情報が異なるシステムに分散していると、AIが適切な情報を参照できず誤った回答を出すリスクがある。
具体例:
FAQとオペレーター向けマニュアルが別々に管理されていたため、AIがFAQの情報しか参照できず、詳細なトラブルシューティングができなかった。これを解決するため、FAQとマニュアルを統合したナレッジベースを構築し、AIが必要な情報を横断的に検索できる仕組みを整えたところ、回答の精度が大幅に向上した。
データの正規化とクリーニング
・ノイズの除去:誤字脱字、不要なデータ、重複データを排除。
・形式の統一:表記ゆれ(例:「クレジットカード」「クレカ」など)を統一し、検索性を向上。
・古い情報の更新:過去のFAQやナレッジデータを定期的に見直し、最新情報を反映。
具体例:
カスタマーサポート用のFAQデータベース内で、「契約変更」と「プラン変更」の2つの表記が混在していたため、AIが一貫性のない回答を生成していた。表記を統一し、AIの学習データを更新した結果、顧客の自己解決率が向上した。
構造化データの活用
・FAQやチャットログのタグ付け:顧客の問い合わせ内容を分類し、適切な回答へ導く。
・階層構造の整理:製品カテゴリや問い合わせ種別ごとにデータを整理し、AIが適切な情報を参照できるようにする。
具体例:
FAQデータがタグ付けされておらず、AIが的確な情報を見つけられなかった。FAQごとに「請求」「解約」「技術的トラブル」などのタグを付与したところ、顧客からの問い合わせに対する回答の精度が向上し、解決までの時間が短縮された。
データの継続的な改善
・フィードバックループの構築:オペレーターや顧客のフィードバックを収集し、回答精度を向上。
・AIの定期的なチューニング:トレンドや顧客のニーズに応じて学習データを更新。
・KPIの設定と評価:正答率、顧客満足度(CSAT)、平均処理時間(AHT)などの指標を定め、効果を測定。
具体例:
AIの回答に対してオペレーターが「適切」「不適切」の評価を付与する仕組みを導入。一定数の「不適切」評価が集まった回答については定期的に見直し、改善を実施したところ、顧客満足度が向上した。
データ整備は一度実施すれば終わるものではなく、継続的な改善が求められます。顧客のニーズや市場環境は常に変化し、それに伴い必要な情報も変化するためです。一度整備したデータも、時間の経過とともに陳腐化し、AIの回答精度を低下させる可能性があるため、定期的な見直しと改善が不可欠となります。
データ整備を成功させるための組織体制

データ整備は、技術的な側面だけでなく、組織的な取り組みも重要です。以下に、データ整備を成功させるための組織体制についても解説します。
データ整備責任者の配置
データ整備を推進するためには、責任者を明確にする必要があります。データ整備責任者は、プロジェクト全体の進捗管理、関係部署との連携、データ品質の維持などを担当します。責任者は、データマネジメントに関する知識と経験を持ち、リーダーシップを発揮できる人材が望ましいです。
データサイエンティストやエンジニアとの連携
データ整備には、データサイエンティストやエンジニアの専門知識が不可欠です。データサイエンティストは、データ分析やモデル構築を担当し、エンジニアは、データ基盤の構築やシステム開発を担当します。これらの専門家と連携し、技術的な側面からデータ整備を推進します。
全社的なデータリテラシー向上
データ整備は、一部の担当者だけでなく、全社的な協力が必要です。従業員全体のデータリテラシーを向上させることで、データに対する意識を高め、データ整備の重要性を理解してもらいます。研修やワークショップなどを通じて、データ活用に関する知識やスキルを習得する機会を提供します。
データ整備チームの組成
コンタクトセンターで実際にあった事例として、データ整備チームを組成し、各部署からメンバーを選出したことで、網羅性の高いデータ整備ができたというものがあります。現場の担当者を巻き込むことで、より実践的で効果的なデータ整備が可能になります。
これらの組織体制を構築し、継続的にデータ整備に取り組むことで、生成AIのポテンシャルを最大限に引き出し、顧客体験の向上、業務効率化、コスト削減といった具体的な成果に繋げることができるでしょう。
まとめ
生成AIを効果的に活用するためには、データの整備が不可欠です。特にコンタクトセンターのような膨大なデータを扱う環境では、ナレッジの統合、データの正規化、構造化データの活用、継続的な改善などが重要なポイントとなります。
データ整備を適切に行うことで、AIの回答精度が向上し、業務効率化や顧客満足度の向上につながります。今後、生成AIの導入を検討する際には、単なるツールの活用にとどまらず、データの管理・最適化にも注力することが成功の鍵となるでしょう。


関連するサービス |
|---|


