専門家コラム

音声認識は、近年のAI技術の進化に伴い、すでに日常生活やビジネスのさまざまな場面において使われています。コンタクトセンター業界においても、業務効率化や顧客満足度の向上を目的に利用の動きが進んでいます。今回は、音声認識の特徴やコンタクトセンターにおける活用ポイントについて、株式会社エーアイスクエアの荻野様に解説していただきました。
音声認識の進化
音声認識は、人が話す声をコンピューターが解析し、テキストに変換する技術のことをいいます。
昨今では、テキスト化だけでなく機器やデバイスに音声で指示出しができるようなサービスも続々と登場しており、「Googleアシスタント」やAppleの「Siri」、スマートスピーカー等、さまざまなサービスが私達の日常生活の利便性を向上させています。
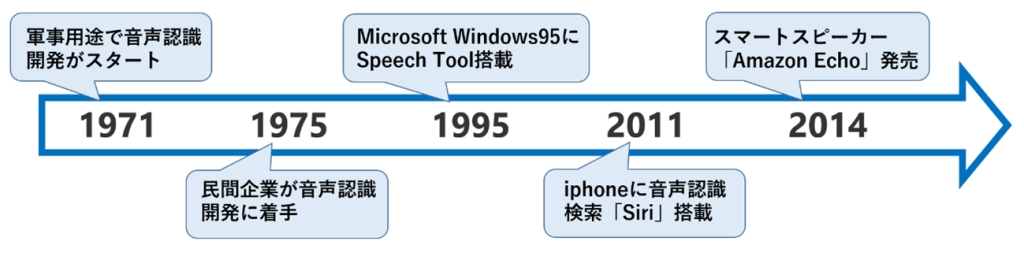
音声認識の歴史は長く、その技術研究は1950年代から始まり、1970年代に本格化しました。
2010年代には、AI、特に深層学習(ディープラーニング)技術の発達により、大規模なデータセットの活用や転移学習等が可能となり、認識精度が格段に向上しました。
これをきっかけにさまざまな製品に音声認識技術が取り入れられるようになり、急速に世の中に普及しました。
(引用元:菱洋エレクトロ株式会社 HP)
音声認識でできること・メリット
音声認識は、主に3つの用途で利用されています。
- 音声アシスタント:音声での質問や指示によりデバイスを操作
- 人間との会話 :人間らしい会話の中で指示を出し、デバイスを操作
- 文字起こし :音声を自動で文字起こし
音声認識を活用することで、ビジネスシーンにおいては、多くのメリットがあります。
- 業務効率化:(例)音声アシスタントによる操作の効率化
- 情報の取得と共有の迅速化:(例)電話クレーム内容の可視化と共有
- データ分析の高度化:(例)問い合わせ内容のテキストマイニング分析
これらのことから、昨今のビジネスシーンにおいて音声認識技術は広く活用されており、会議の議事録自動作成や通訳時の多言語翻訳、医療機関での電子カルテ作成、工場での音声による機器自動操作等、さまざまな業務の高度化に寄与しています。
コンタクトセンターにおける音声認識の活用
コンタクトセンターにおいても、人手不足や顧客満足度の向上、データ分析等のさまざまな観点から、音声認識の活用が急速に進んでいます。

コンタクトセンターにおける音声認識活用の重要なポイントは2つです。
- 認識精度自体の向上
- 認識テキストの活用
それぞれのポイントについて解説します。
認識精度自体の向上
認識精度の向上について触れる前に、まずは音声認識の仕組みについて解説します。
音声認識の工程は、「音声分析」と「探索」に分かれます。
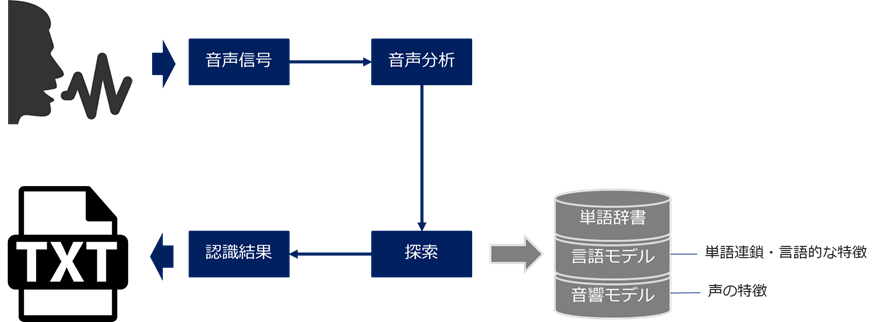
<音声分析>
入力した音声を、コンピューターが認識しやすいデータに加工する作業です。音声の周波数や強弱、音同士の間隔、時系列などのさまざまな特徴を、「特徴量」と呼ばれる数値に変換し加工していきます。
<探索>
「音素」の特定や、単語への変換、文章出力を行う作業です。
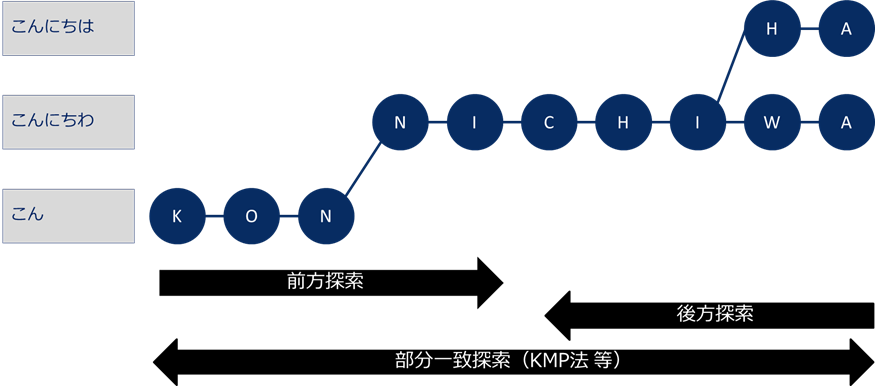
まずは「音響モデル」によって、抽出された音声の特徴量がどの「音素」にどれくらい近いかを計算します。「音素」とは音声の中に含まれる母音、子音、撥音(ン)の3つの要素を指します。※例 言葉:「こんにちは」⇒音素:「K-O-N-N-I-C-H-I-H-A」(この一文字ずつが音素)。
抽出した音素は、「単語辞書」で意味のある日本語に変換していきます。「単語辞書」とは、音素の並びとそれに対応した単語のDBで、単語は音素を木構造データとして保有しています。この辞書データと音素をパターンマッチ(正解データと照らし合わせて同一=正解とする手法)によって探索していきます。探索の方法は、「前方探索」や「後方探索」、「部分一致探索」等のさまざまな方法があります。
変換された単語群は、「言語モデル」によって組み合わされ文章化されます。
「言語モデル」では、ある単語から次の単語に移動する際に、どの位その繋がりの確率が起こるのかを定義しています。
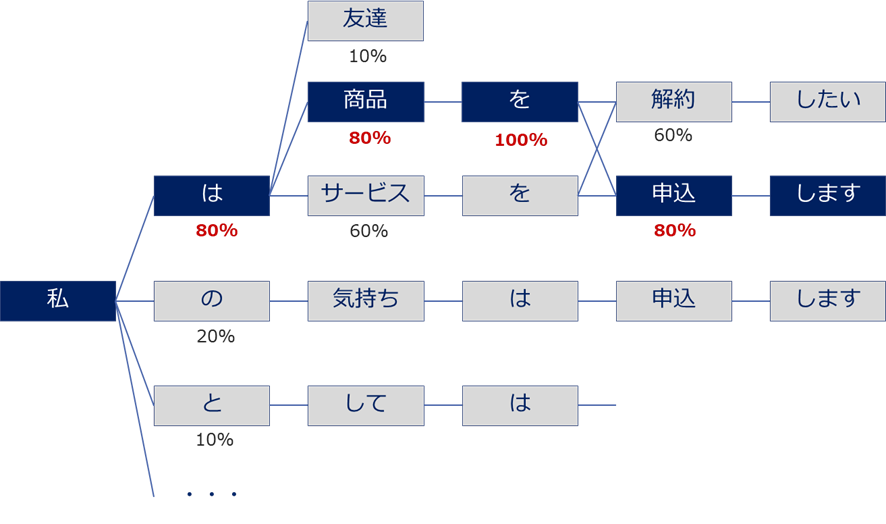
統計的に高い確率の組み合わせが選ばれる事によって、自然な文章が作成され、認識テキストとして出力されます。
これらの工程の中で音声認識の精度を向上させるポイントは、入力する「音声の質」と、音素特定や単語変換を行う「エンジンの認識率」の部分となります。

集音環境やオペレーターの話し方の改善といった音声側のアプローチと、音声データや聞き起こしテキストの追加学習、辞書登録といったエンジン側のアプローチがあります。
現状の認識上の課題を明確化し、適切なアプローチを取る事が重要です。
認識テキストの活用
音声認識精度を上げたとしても、以下のような点から、認識テキストの活用に課題を抱えるコンタクトセンターは少なくありません。
- うなずきやフィラー等のノイズが含まれている
- 一連の発話が複数行に分割されている
- 同一行内に複数の発話が含まれている
- 話し言葉で読みづらい
このようなテキストは、テキストマイニングや要約、FAQレコメンド等に活用する事が困難です。
音声認識ベンダーは、ノイズ等も含めて正確に「データ化」する事が役割となり、テキストの「活用」については言語処理ベンダーの役割と考えています。
データのクレンジングや書き言葉変換、高精度なゆらぎ吸収等、テキストを活用するための機能が備わったソリューションの選定が重要です。
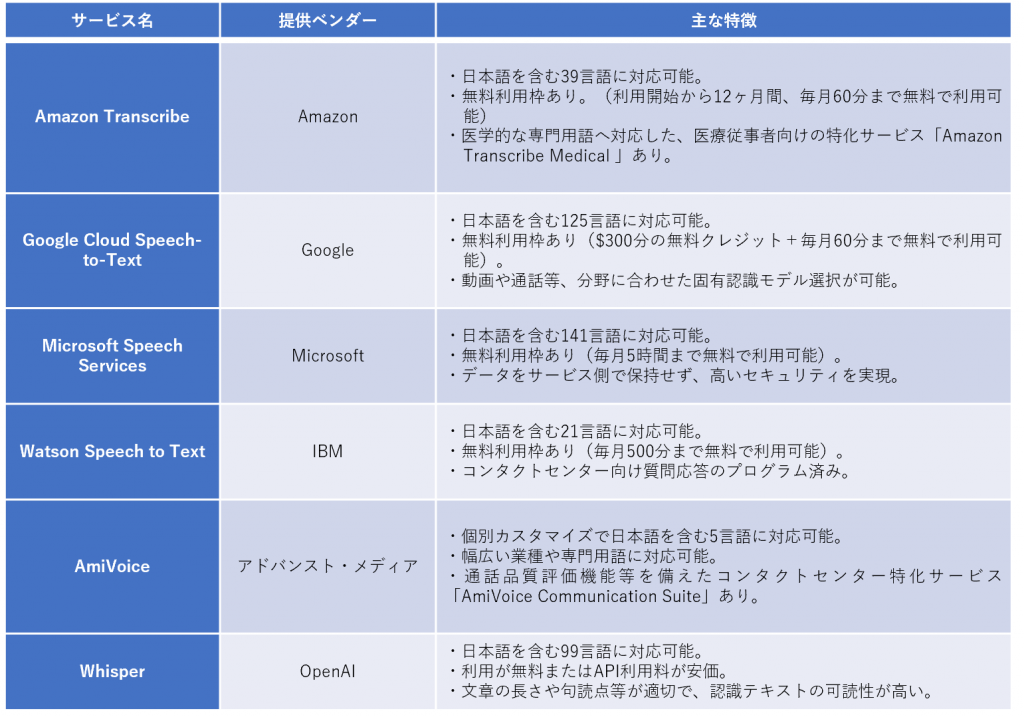
主要な音声認識サービス
音声認識サービスは数多くありますが、主要なものを以下に紹介します。
音声認識サービスはさまざまありますが、今、精度の高さと安価で利用できる点から、特に注目を集めているのが「Whisper」です。
WhisperはアメリカのOpenAIが開発している音声認識で、Web上から収集した68万時間もの音声データから学習されています。
従来の事前学習モデルは、特徴量の異なるデータを利用する場合に都度モデルのチューニングが必要だったのに対し、Whisperはチューニングなしに高精度を出すことができます。
利用方法はAPIとOSSがあり、API利用の場合でも、料金は$0.006/分と非常に安価で手軽に利用できます。
音声認識サービスWhisperについて
Whisperは、多言語の音声認識や音声翻訳、言語認識等を非常に高い精度で行うことが可能です。
多言語での会議議事録作成や動画編集における字幕作成等、さまざまな業務用途に使われはじめています。
当然ながらコンタクトセンター領域においても活用でき、多言語コンタクトセンターの構築や、感情分析や質問応答、要約等の技術と組み合わせて利用することで、業務の高度化につなげられます。
幅広い業務に適用可能なため、Whisperの利用率は今後さらに拡大していくと予想されます。
Whisperの音声認識精度
Whisperには5つのモデルがあり、目的別に利用できるようになっています。モデルサイズが小さいほど処理速度が速く、大きくなるほど書き起こしの精度が上がります。
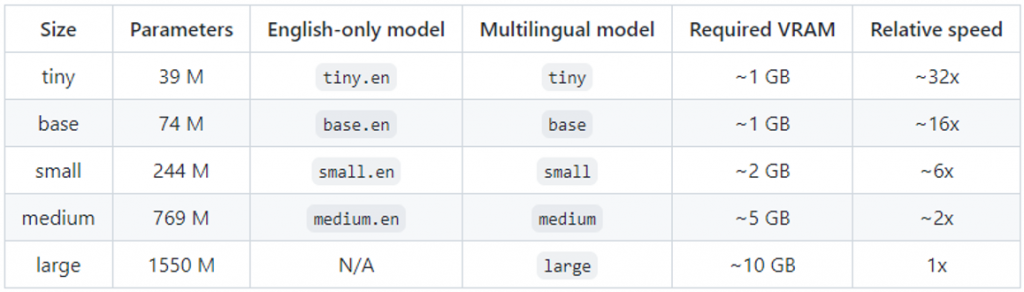 (引用元:https://github.com/openai/whisper)
(引用元:https://github.com/openai/whisper)
では、Whisperの精度は具体的にどの程度なのでしょうか。
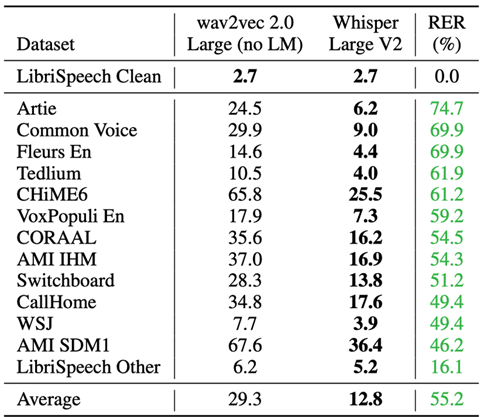
音声認識の精度評価指標の一つとして、WER(Word Error Rate)という、認識テキスト内の単語誤り率を示したものがあります。
下記は英語の音声認識テストによって、Whisperのlargeモデルと従来の認識手法wav2vec 2.0のWERを比較した表です(縦軸中央がWER(%))。
 (引用元:https://cdn.openai.com/papers/whisper.pdf#page=6)
(引用元:https://cdn.openai.com/papers/whisper.pdf#page=6)
※WER=(挿入単語数 + 置換単語数 + 削除単語数)/正解単語数
※RER= Whisperに対してのwav2vec2.0からのWER減少率
Whisperでの認識結果は、従来手法よりもWERが低くなっており、高い精度で認識できていることが分かります。
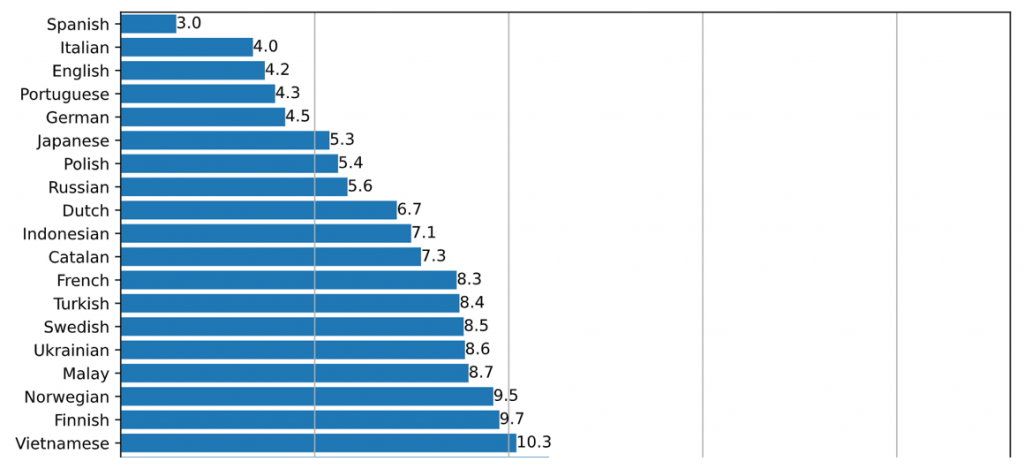
また、日本語の認識精度が高い点も特徴です。
下記は、言語別のWERスコアを昇順にした表(一部抜粋)です。日本語は全体で6位の「5.3%」となっており、その他言語と比較しても特に高い精度を出しています。
 (引用元:https://github.com/openai/whisper)
(引用元:https://github.com/openai/whisper)
当社でもWhisperの提供を行っております。
また、要約やチャットボット等、音声認識後のテキストを実務で活用するための各種サービスも合わせて提供しており、包括的な業務のご支援を行っています。
音声認識を活用して顧客応対を改善するために
ビジネス環境や消費行動の変化から、昨今の企業にはCX(顧客体験)の向上が求められており、特にコンタクトセンターでの顧客応対はその重要な役割を担っています。
応対品質管理や業務効率化、VoC分析による応対やサービス上の課題の洗い出しを行うためには、まずは音声認識によって問い合わせ内容をテキスト化し、可視化することが重要です。
当社では音声認識はさることながら、業務高度化のための各種サービスも提供しております。「音声認識を入れるべきか迷っている」「活用の仕方を知りたい」など、お悩みがございましたらお気軽にご相談ください。

関連するサービス |
|---|


